清单¶
清单是 Turbo EA 的核心。这里列出了企业架构的所有卡片(组件):应用程序、流程、业务能力、组织、供应商、接口等等。
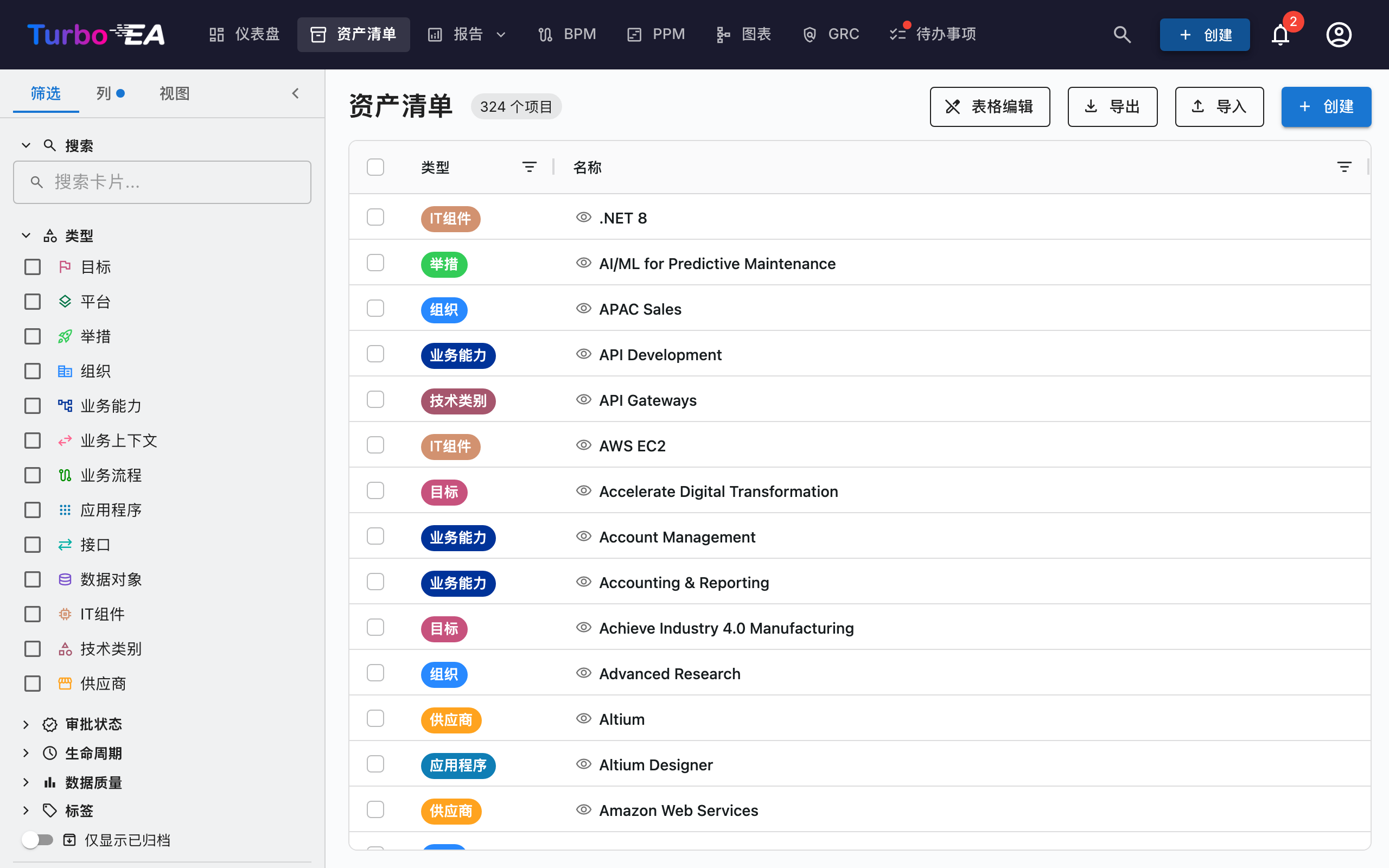
清单界面结构¶
左侧筛选面板¶
左侧边栏面板允许您按不同条件筛选卡片:
- 搜索 —— 按卡片名称进行自由文本搜索
- 类型 —— 按一种或多种卡片类型筛选:目标、平台、项目、组织、业务能力、业务上下文、业务流程、应用程序、接口、数据对象、IT 组件、技术类别、供应商、系统
- 子类型 —— 选择类型后,可进一步按子类型筛选(例如,应用程序 → 业务应用、微服务、AI 代理、部署)
- 审批状态 —— 草稿、已批准、已变更或已拒绝
- 生命周期 —— 按生命周期阶段筛选:规划、引入、活跃、淘汰、生命周期结束
- 数据质量 —— 基于阈值筛选:良好(80%+)、中等(50-79%)、较差(低于 50%)
- 标签 —— 按任何标签组的标签筛选
- 关系 —— 按跨关系类型的关联卡片筛选
- 自定义属性 —— 按自定义字段的值筛选(文本搜索、选择选项)
- 仅显示已归档 —— 切换查看已归档(软删除)的卡片
- 清除全部 —— 一次性重置所有活跃筛选条件
活跃筛选数量徽章显示当前应用了多少个筛选条件。
列选项卡¶
侧面板中的列选项卡允许您选择在网格中显示哪些附加列。可用列会根据所选卡片类型动态变化:
- 选择单个类型 —— 该类型定义的所有属性字段均可用,包括关系列和元数据列
- 选择多个类型 —— 仅显示所有选定类型共有的字段
- 未选择类型 —— 提示信息建议您先选择一个卡片类型
列分为四个类别:
| 类别 | 描述 |
|---|---|
| 默认列 | 始终显示的列:类型、名称、路径、描述、子类型、生命周期、审批状态、数据质量。取消勾选可将其从表格中隐藏 — 有助于将已保存的视图收紧为您真正使用的列。 |
| 元数据 | 创建时间、修改时间、创建者、修改者 |
| 属性 | 在元模型中定义的自定义字段(文本、数字、成本、日期、选择等) |
| 关系 | 关联的卡片类型(例如,与业务能力关联的应用程序) |
路径列显示卡片的层级面包屑(例如「北美 / 销售 / 内部销售」),不包含卡片自身的名称,因此可以同时显示「名称」和「路径」。
每个类别都有一个全选复选框,可快速切换该组中的所有列。顶部的搜索框可按名称查找特定列。每个分区标题上的徽章显示该组中当前可见的列数。
首次选择卡片类型时,所有属性列和关系列默认启用。之后您可以取消勾选不需要的列。「列」选项卡底部的重置按钮可恢复默认列选择。
当列选择与默认值不同时,「列」选项卡标题上会出现变更指示点。同样的指示器也会出现在筛选器选项卡上(当有活动筛选器时),便于一目了然地看到哪些设置已被修改。
您的列选择、活动筛选器和排序顺序会自动保存在浏览器中。返回库存页面时,系统会恢复您之前的配置。保存的视图(书签)也会保留完整的列选择,因此在视图之间切换时会完全恢复您配置的列。
主表格¶
清单使用 AG Grid 数据表格,具有强大的功能:
| 列 | 描述 |
|---|---|
| 类型 | 带颜色编码图标的卡片类型 |
| 名称 | 组件名称(点击打开卡片详情) |
| 描述 | 简要描述 |
| 生命周期 | 当前生命周期状态 |
| 审批状态 | 审核状态徽章 |
| 数据质量 | 带可视化圆环的完整度百分比 |
| 关系 | 关系数量,可点击弹出窗口显示关联卡片 |
表格功能:
- 排序 —— 点击任何列标题进行升序/降序排序
- 行内编辑 —— 在网格编辑模式下,直接在表格中编辑字段值
- 多选 —— 选择多行进行批量操作
- 层级显示 —— 父子关系以面包屑路径显示
- 列配置 —— 显示、隐藏和重新排列列
工具栏¶
- 网格编辑 —— 切换行内编辑模式以在表格中编辑多张卡片
- 导出 —— 以 Excel (.xlsx) 文件下载数据
- 导入 —— 从 Excel 文件批量上传数据
- + 创建 —— 创建新卡片
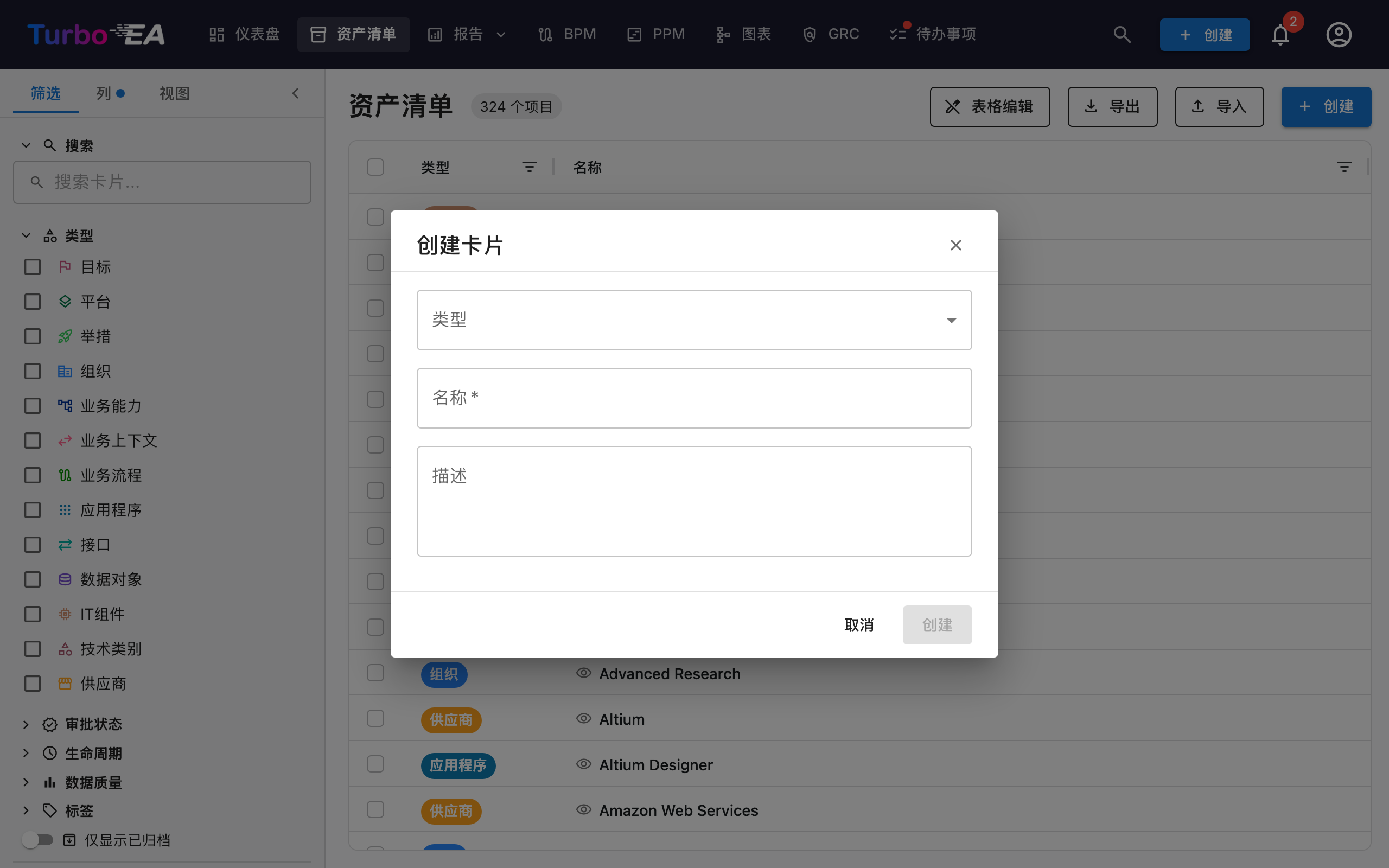
如何创建新卡片¶
- 点击+ 创建按钮(蓝色,右上角)
- 在弹出的对话框中:
- 选择卡片的类型(应用程序、流程、目标等)
- 输入组件的名称
- 可选填写描述
- 可选点击AI 建议自动生成描述(参见下方 AI 描述建议)
- 点击创建
AI 描述建议¶
Turbo EA 可以使用 AI 为任何卡片生成描述。此功能适用于创建卡片对话框和现有卡片详情页面。
工作原理:
- 输入卡片名称并选择类型
- 点击卡片标题中的星光图标,或在创建卡片对话框中点击AI 建议按钮
- 系统执行网络搜索(使用类型感知的上下文 —— 例如「SAP S/4HANA 软件应用程序」),然后将结果发送给 LLM 生成简洁、事实性的描述
- 建议面板显示:
- 可编辑的描述 —— 在应用前查看和修改文本
- 置信度评分 —— 表示 AI 的确定程度(高 / 中 / 低)
- 可点击的来源链接 —— 描述所引用的网页
- 模型名称 —— 生成建议的 LLM
- 点击应用描述保存,或点击取消放弃
主要特点:
- 类型感知:AI 理解卡片类型上下文。「应用程序」搜索会添加「软件应用程序」,「供应商」搜索会添加「技术供应商」等。
- 隐私优先:使用 Ollama 时,LLM 在本地运行 —— 您的数据永远不会离开您的基础设施。也支持商业提供商(OpenAI、Google Gemini、Anthropic Claude 等)
- 管理员控制:AI 建议必须由管理员在设置 > AI 建议中启用。管理员选择哪些卡片类型显示建议按钮,配置 LLM 提供商,以及选择网络搜索提供商
- 基于权限:只有拥有
ai.suggest权限的用户才能使用此功能(默认对管理员、BPM 管理员和成员角色启用)
已保存视图(书签)¶
您可以将当前的筛选、列和排序配置保存为命名视图以便快速复用。
创建已保存视图¶
- 按您期望的筛选条件、列和排序配置清单
- 点击筛选面板中的书签图标
- 输入视图的名称
- 选择可见性:
- 私有 —— 仅您可见
- 共享 —— 对特定用户可见(可选编辑权限)
- 公开 —— 对所有用户可见
使用已保存视图¶
已保存视图显示在筛选面板侧边栏中。点击任何视图可立即应用其配置。视图按以下类别组织:
- 我的视图 —— 您创建的视图
- 与我共享 —— 他人与您共享的视图
- 公开视图 —— 所有人可用的视图
Excel 导入 / 导出¶
清单的导入和导出使用多工作表 Excel 工作簿,可完整往返一个子景观——任意数量类型的卡片以及它们之间的关系——无需复制任何 UUID。
工作簿结构¶
- 每个卡片类型一个工作表(Application、Business Capability、IT Component、……),包含核心列、
attr_<字段>自定义属性列、生命周期列以及rel:<关系类型>关系列。 Relations工作表用于携带属性的关系类型(成本、描述等)。简单关系仍保留在源卡片工作表的内联单元格中。_Meta工作表记录工作簿格式版本。
无 GUID 识别¶
当卡片名称在其类型内唯一时按名称识别,否则按完整的 parent_path 识别。若仅有一张 Application 名为 NexaCore ERP,关系单元格可直接写 NexaCore ERP;若名称重复,使用 Sales / Customer Mgmt / CRM。
同级唯一性¶
由于卡片按"名称 + 路径"识别,同一类型的两张卡片不能同时拥有相同的父级与相同的名称。任何会产生此类冲突的新卡片在创建时都会被拒绝(包括"创建卡片"对话框、内联重命名以及表格导入)。数据库中已有的重复项(来自旧 Seed 或导入)保持不变 —— 您可以编辑它们的任何字段,但创建第三个重复或将卡片重命名回冲突状态会被阻止。比较时忽略大小写和首尾空白,与导入器的解析器一致。
内联关系单元格¶
每个 rel:<关系类型> 列以分号分隔的目标引用表达出向关系(例如 NexaCore ERP; BillingApp)。使用分号而非逗号,因为卡片名称中常包含逗号(如 Acme, Inc.)。名称内的 / 与 \ 会被转义为 \/ 与 \\ —— 导出器会自动处理(例如 SAP S/4HANA → SAP S\/4HANA)。单元格是声明式的:单元格内容会替换该类型下源卡片的全部出向关系。从列表中移除一个目标会删除对应关系;清空单元格则全部删除。为兼容旧版本,导入器仍接受以逗号分隔的单元格。
Relations 工作表¶
对于带属性的关系,请使用专用工作表,列为:relation_type、source_ref、target_ref、action(默认 upsert,可选 delete)、attr_<字段> 以及 description。
导入¶
点击工具栏中的导入,将工作簿拖入对话框并在应用前查看预览。你会看到要创建/更新的卡片,以及要新增/移除的关系。错误(例如目标不明确并列出候选路径)会阻止应用。
导出¶
点击工具栏中的导出。当前过滤决定内容:单类型过滤时仅导出该类型的工作表;不过滤或多类型时按存在的每种类型导出一个工作表。任一情况下工作簿都包含 Relations 与 _Meta,可重新导入且不会丢失类型特定的属性。
文档导入¶
Turbo EA 可以使用您配置的 AI 提供商从非结构化文档(PDF、Word 文档、纯文本或 RTF)中提取卡片。当从供应商 RFP、架构报告、Wiki 导出或任何按名称提及应用程序、能力、流程、数据对象或 IT 组件的长篇散文中引入景观时非常有用。
从工具栏的导入 ▾ → 文档(PDF、Word、文本)打开此流程。
工作原理¶
拖放文件(或点击浏览),分析后对话框将显示三个部分:
- 现有匹配项 — 系统在文档中识别到的、已存在于您景观中的卡片,每张卡片均显示置信度百分比。当同一名称的多个变体指向同一张卡片时(例如「NexaCore」、「NexaCore ERP」、「Nexa Core 平台」),它们将合并为一行 — 显示置信度最高的变体匹配文本。
- 建议的卡片 — 文档中提及但尚不存在的新卡片。每个条目都有一个复选框(默认勾选)、AI 推断的类型(Application、BusinessCapability、BusinessProcess 等)、引用次数,以及可选的:
- 生命周期标签 — 显示检测到的阶段和日期(例如
活跃 · 2023-06-01)。若检测到阶段但未找到日期,则使用导入日期(今天)。 - 描述预览 — 文档中关于该实体的一两句摘要,以斜体显示。
- 生命周期标签 — 显示检测到的阶段和日期(例如
- 建议的关系 — AI 在发现的实体之间识别出的关联。每行显示方向(「来源 — 标签 → 目标」)及复选框。若上方任一端点卡片未勾选,该关系将自动禁用。
取消勾选不需要的项目,然后点击导入 N 个已选。标准创建卡片对话框将逐个为每个剩余建议打开,并预填 AI 的名称、类型、描述和生命周期。您可以在保存前调整一切。取消某步骤会跳过该建议;当所有卡片创建完成后,已启用的关系将自动创建,您将返回清单网格。
分析模式¶
文件名旁的小徽章会显示使用了哪种提取器:
- AI 分析 — 您配置的 LLM 提供商提取了候选项并将其与现有卡片进行匹配。通常每次导入两次 LLM 调用(一次用于提取,一次用于匹配)。
- 模式分析 — 内置的正则表达式提取器替代运行。触发条件:
- 在管理设置中禁用了 AI,或
- AI 调用在提取过程中失败(响应会优雅回退,确保您始终获得结果),或
- 您的景观中存在超过 2 000 张活跃卡片(AI 解析器的软限制;
difflib模糊匹配接管以保持提示词在可控范围内)。
如果 AI 已启用但配置错误(模型 ID 为空,或商业提供商缺少 API 密钥),对话框将返回与 AI 描述建议 行为相同的红色错误。在管理员 → 设置 → AI 中修复模型/密钥后重试。
大型文档¶
大到需要多次 LLM 调用的文档(每个块 ≥ 30 KB 提取文本)在任何提供商调用前会触发确认步骤。对话框会显示块数和大致调用次数;点击继续以继续,或点击取消以不消耗令牌地中止。
支持的格式¶
| 格式 | 扩展名 | 备注 |
|---|---|---|
.pdf |
可提取文本的 PDF;扫描图像 PDF 不返回文本 | |
| Word | .docx、.doc |
读取正文段落;嵌入的表格和标题可能被跳过 |
| 纯文本 | .txt |
UTF-8 |
| 富文本 | .rtf |
解码为 UTF-8 |
最大文件大小:10 MB。
权限¶
对于拥有 documents.view 权限的用户,「文档」选项会出现在导入菜单中。实际的 AI 提取使用与 AI 描述建议相同的提供商配置,并受相同的管理员设置控制 — 请参阅上方的 AI 描述建议 了解提供商和模型设置。