Inventaire¶
L'Inventaire est le cœur de Turbo EA. Toutes les fiches (composants) de l'architecture d'entreprise y sont listées : applications, processus, capacités métier, organisations, fournisseurs, interfaces, et plus encore.
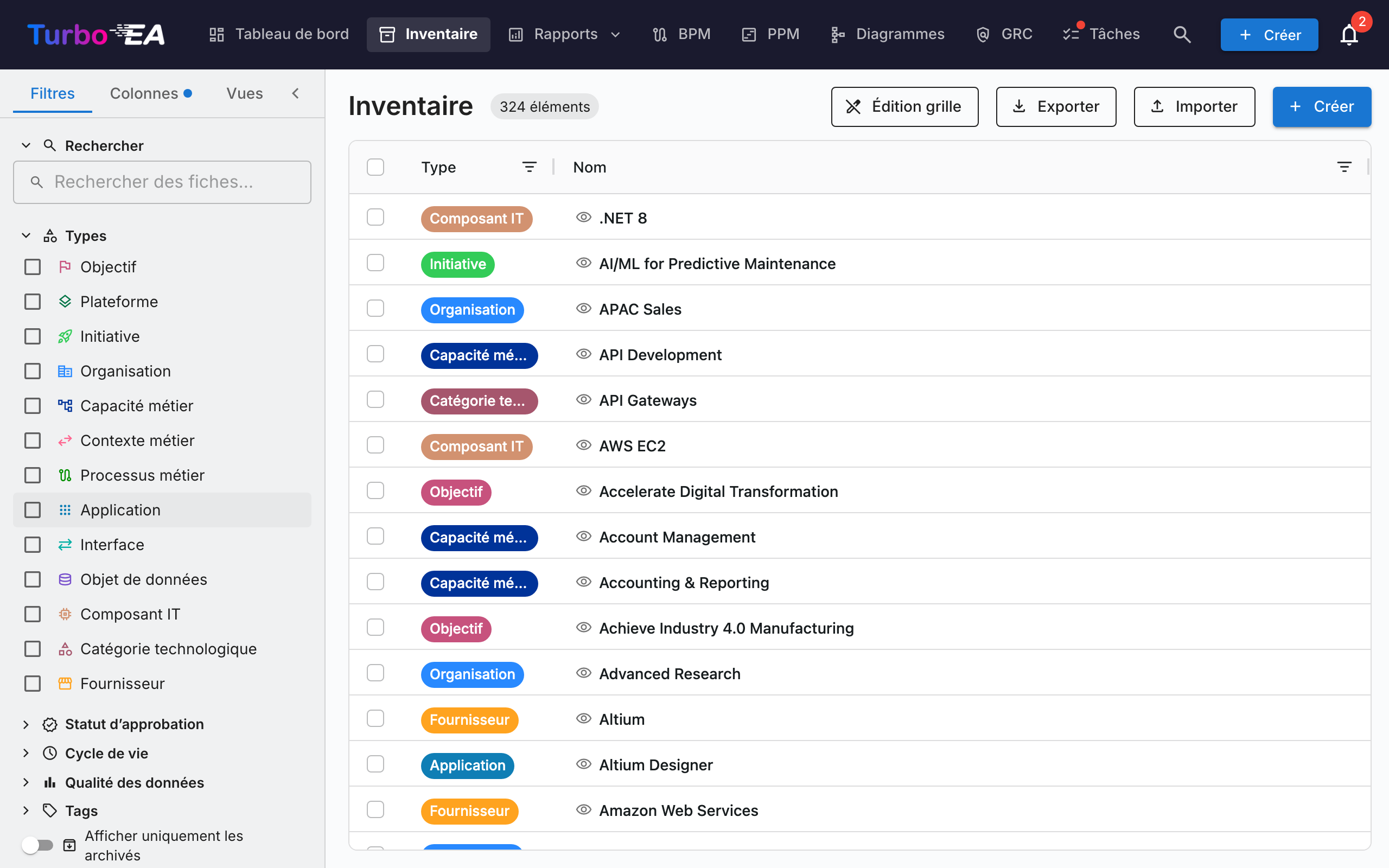
Structure de l'écran d'inventaire¶
Panneau de filtres à gauche¶
Le panneau latéral gauche permet de filtrer les fiches selon différents critères :
- Recherche -- Recherche en texte libre sur les noms de fiches
- Types -- Filtrer par un ou plusieurs types de fiches : Objectif, Plateforme, Initiative, Organisation, Capacité Métier, Contexte Métier, Processus Métier, Application, Interface, Objet de Données, Composant IT, Catégorie Technique, Fournisseur, Système
- Sous-types -- Lorsqu'un type est sélectionné, filtrer davantage par sous-type (par ex. Application -> Application Métier, Microservice, Agent IA, Déploiement)
- Statut d'approbation -- Brouillon, Approuvé, Cassé ou Rejeté
- Cycle de vie -- Filtrer par phase du cycle de vie : Planification, Mise en service, Actif, Retrait progressif, Fin de vie
- Qualité des données -- Filtrage par seuil : Bonne (80%+), Moyenne (50-79%), Faible (inférieure à 50%)
- Tags -- Filtrer par tags de n'importe quel groupe de tags
- Relations -- Filtrer par fiches liées à travers les types de relations
- Attributs personnalisés -- Filtrer par valeurs dans les champs personnalisés (recherche textuelle, options de sélection)
- Afficher uniquement les archives -- Basculer pour voir les fiches archivées (supprimées de manière logique)
- Tout effacer -- Réinitialiser tous les filtres actifs d'un coup
Un badge de nombre de filtres actifs indique combien de filtres sont actuellement appliqués.
Onglet Colonnes¶
L'onglet Colonnes dans le panneau latéral vous permet de choisir les colonnes supplémentaires à afficher dans la grille. Les colonnes disponibles changent dynamiquement en fonction des types de cartes sélectionnés :
- Un seul type sélectionné — Tous les champs d'attributs définis pour ce type sont disponibles, ainsi que les colonnes de relations et de métadonnées
- Plusieurs types sélectionnés — Seuls les champs communs à tous les types sélectionnés sont disponibles
- Aucun type sélectionné — Un message d'indication vous invite à sélectionner d'abord un type de carte
Les colonnes sont regroupées en quatre catégories :
| Catégorie | Description |
|---|---|
| Colonnes par défaut | Colonnes toujours actives : Type, Nom, Chemin, Description, Sous-type, Cycle de vie, Statut d'approbation, Qualité des données. Décochez-les pour les masquer de la grille — utile pour resserrer une vue enregistrée aux seules colonnes que vous utilisez vraiment. |
| Métadonnées | Créé, Modifié, Créé par, Modifié par |
| Attributs | Champs personnalisés définis dans le métamodèle (texte, nombre, coût, date, sélection, etc.) |
| Relations | Types de cartes liés (par ex., Applications liées à une Capacité Métier) |
La colonne Chemin affiche le fil d'Ariane hiérarchique (par ex. « Amérique du Nord / Ventes / Ventes internes ») sans le nom de la fiche elle-même, ce qui vous permet d'afficher Nom et Chemin en même temps.
Chaque catégorie dispose d'une case à cocher Tout sélectionner pour activer ou désactiver rapidement toutes les colonnes du groupe. Un champ de recherche en haut permet de trouver des colonnes spécifiques par nom. Le badge sur chaque en-tête de section indique combien de colonnes de ce groupe sont actuellement visibles.
Lorsqu'un type de carte est sélectionné pour la première fois, toutes les colonnes d'attributs et de relations sont activées par défaut. Vous pouvez ensuite décocher les colonnes dont vous n'avez pas besoin. Un bouton Réinitialiser en bas de l'onglet « Colonnes » restaure la sélection de colonnes par défaut.
Un point indicateur de modification apparaît sur l'en-tête de l'onglet « Colonnes » lorsque la sélection de colonnes diffère des valeurs par défaut. Le même indicateur apparaît sur l'onglet Filtres lorsque des filtres sont actifs, permettant de voir d'un coup d'œil quels paramètres ont été modifiés.
Votre sélection de colonnes, vos filtres actifs et votre ordre de tri sont automatiquement conservés dans votre navigateur. Lorsque vous revenez à la page d'inventaire, votre configuration précédente est restaurée. Les vues enregistrées (signets) conservent également la sélection complète des colonnes, de sorte que le passage d'une vue à l'autre restaure exactement les colonnes que vous aviez configurées.
Tableau principal¶
L'inventaire utilise un tableau de données AG Grid avec des fonctionnalités puissantes :
| Colonne | Description |
|---|---|
| Type | Type de fiche avec icône colorée |
| Nom | Nom du composant (cliquer pour ouvrir le détail de la fiche) |
| Description | Description brève |
| Cycle de vie | État actuel du cycle de vie |
| Statut d'approbation | Badge de statut de révision |
| Qualité des données | Pourcentage de complétude avec anneau visuel |
| Relations | Nombre de relations avec popover cliquable affichant les fiches liées |
Fonctionnalités du tableau :
- Tri -- Cliquer sur l'en-tête de n'importe quelle colonne pour trier par ordre croissant/décroissant
- Édition en ligne -- En mode édition grille, modifiez les valeurs des champs directement dans le tableau
- Sélection multiple -- Sélectionnez plusieurs lignes pour des opérations en masse
- Affichage hiérarchique -- Les relations parent/enfant sont affichées sous forme de chemins de navigation
- Configuration des colonnes -- Afficher, masquer et réorganiser les colonnes
Barre d'outils¶
- Édition grille -- Basculer le mode d'édition en ligne pour modifier plusieurs fiches dans le tableau
- Exporter -- Télécharger les données sous forme de fichier Excel (.xlsx)
- Importer ▾ -- Menu déroulant avec deux options :
- Feuille de calcul (Excel/CSV) -- Chargement en masse de données structurées via le classeur multi-feuilles avec relations. Voir Import / Export Excel ci-dessous.
- Document (PDF, Word, texte) -- Extraire des fiches d'un document non structuré via votre fournisseur IA configuré. Voir Import de documents ci-dessous.
- + Créer -- Créer une nouvelle fiche
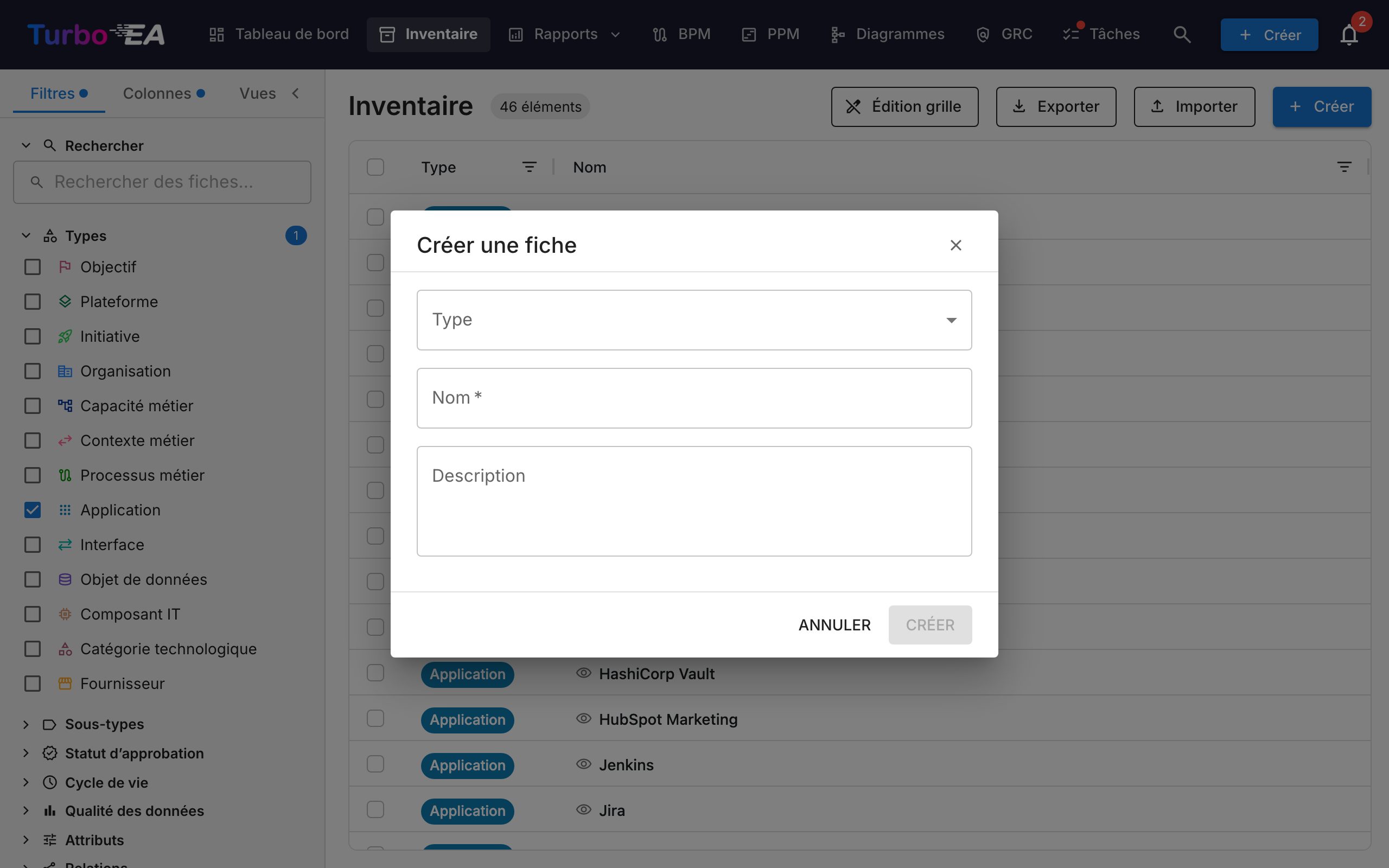
Comment créer une nouvelle fiche¶
- Cliquez sur le bouton + Créer (bleu, coin supérieur droit)
- Dans la boîte de dialogue qui apparaît :
- Sélectionnez le Type de fiche (Application, Processus, Objectif, etc.)
- Entrez le Nom du composant
- Optionnellement, ajoutez une Description
- Optionnellement, cliquez sur Suggérer avec l'IA pour générer automatiquement une description (voir Suggestions de description par IA ci-dessous)
- Cliquez sur CREER
Suggestions de description par IA¶
Turbo EA peut utiliser l'IA pour générer une description pour n'importe quelle fiche. Cela fonctionne aussi bien dans la boîte de dialogue de création de fiche que sur les pages de détail des fiches existantes.
Comment ça marche :
- Entrez un nom de fiche et sélectionnez un type
- Cliquez sur l'icône étincelle dans l'en-tête de la fiche, ou le bouton Suggérer avec l'IA dans la boîte de dialogue de création de fiche
- Le système effectue une recherche web pour le nom de l'élément (en utilisant un contexte adapté au type -- par ex. « SAP S/4HANA software application »), puis envoie les résultats à un LLM pour générer une description concise et factuelle
- Un panneau de suggestion apparaît avec :
- Description modifiable -- examinez et modifiez le texte avant de l'appliquer
- Score de confiance -- indique le degré de certitude de l'IA (Élevé / Moyen / Faible)
- Liens sources cliquables -- les pages web d'où provient la description
- Nom du modèle -- quel LLM a généré la suggestion
- Cliquez sur Appliquer la description pour sauvegarder, ou Ignorer pour rejeter
Caractéristiques clés :
- Adapté au type : L'IA comprend le contexte du type de fiche. Une recherche « Application » ajoute « software application », une recherche « Fournisseur » ajoute « technology vendor », etc.
- Confidentialité d'abord : Lorsque vous utilisez Ollama, le LLM s'exécute localement -- vos données ne quittent jamais votre infrastructure. Les fournisseurs commerciaux (OpenAI, Google Gemini, Anthropic Claude, etc.) sont également pris en charge
- Contrôle par l'administrateur : Les suggestions IA doivent être activées par un administrateur dans Paramètres > Suggestions IA. Les administrateurs choisissent quels types de fiches affichent le bouton de suggestion, configurent le fournisseur LLM et sélectionnent le fournisseur de recherche web
- Basé sur les permissions : Seuls les utilisateurs disposant de la permission
ai.suggestpeuvent utiliser cette fonctionnalité (activée par défaut pour les rôles Admin, Admin BPM et Membre)
Vues sauvegardées (Signets)¶
Vous pouvez sauvegarder votre configuration actuelle de filtres, colonnes et tri sous forme de vue nommée pour une réutilisation rapide.
Créer une vue sauvegardée¶
- Configurez l'inventaire avec les filtres, colonnes et tri souhaités
- Cliquez sur l'icône signet dans le panneau de filtres
- Entrez un nom pour la vue
- Choisissez la visibilité :
- Privée -- Seul vous pouvez la voir
- Partagée -- Visible par des utilisateurs spécifiques (avec des permissions de modification optionnelles)
- Publique -- Visible par tous les utilisateurs
Utiliser les vues sauvegardées¶
Les vues sauvegardées apparaissent dans la barre latérale du panneau de filtres. Cliquez sur n'importe quelle vue pour appliquer instantanément sa configuration. Les vues sont organisées en :
- Mes vues -- Vues que vous avez créées
- Partagées avec moi -- Vues que d'autres ont partagées avec vous
- Vues publiques -- Vues disponibles pour tous
Import / Export Excel¶
Les exports et imports d'inventaire utilisent un classeur Excel multi-feuilles qui restitue l'intégralité d'un sous-paysage — fiches de tous types et relations entre elles — sans jamais exiger de copier un UUID.
Ouvrez ce flux via Importer ▾ → Feuille de calcul (Excel/CSV) dans la barre d'outils.
Structure du classeur¶
- Une feuille par type de fiche (Application, Business Capability, IT Component, …) avec ses colonnes principales, ses
attr_<champ>, ses colonnes de cycle de vie, et ses colonnesrel:<type_de_relation>. - Une feuille
Relationspour les types de relation qui portent des attributs (coût, description, …). Les relations simples restent en ligne sur la feuille de la fiche source. - Une feuille
_Metacontenant la version du format du classeur.
Identification sans GUID¶
Les fiches sont identifiées par leur nom lorsqu'il est unique dans son type, sinon par leur parent_path complet. Une cellule de relation peut écrire NexaCore ERP directement si une seule Application porte ce nom ; en cas d'homonymie, on utilise Sales / Customer Mgmt / CRM.
Unicité des fiches sœurs¶
Parce que les fiches sont identifiées par nom + chemin, deux fiches du même type ne peuvent pas partager à la fois le même parent et le même nom. Les nouvelles fiches qui créeraient une telle collision sont rejetées à la création (dans la boîte de dialogue Créer, en renommage inline et lors de l'import Excel). Les doublons déjà présents en base, hérités d'imports ou de seeds antérieurs, restent intacts — vous pouvez modifier n'importe quel champ, mais re-créer un troisième doublon ou renommer une fiche pour recréer la collision est bloqué. La comparaison est insensible à la casse et aux espaces, comme le résolveur de l'import.
Cellules de relation en ligne¶
Chaque colonne rel:<type_de_relation> exprime les relations sortantes sous forme de cibles séparées par des points-virgules (par exemple NexaCore ERP; BillingApp). Point-virgule plutôt que virgule, car les noms de fiches contiennent souvent des virgules (Acme, Inc.). À l'intérieur d'un nom, / et \ sont échappés en \/ et \\ — l'exporteur s'en charge automatiquement (par ex. SAP S/4HANA → SAP S\/4HANA). Les cellules sont déclaratives : leur contenu remplace l'ensemble des relations sortantes de ce type depuis la source. Retirer une cible supprime la relation correspondante ; vider la cellule les supprime toutes. Pour rétrocompatibilité, les cellules séparées par des virgules (ancien format) restent acceptées.
Feuille Relations¶
Pour les relations avec attributs, utilisez la feuille dédiée Relations avec les colonnes relation_type, source_ref, target_ref, action (par défaut upsert, sinon delete), attr_<champ> et description.
Import¶
Cliquez sur Importer dans la barre d'outils, déposez le classeur et vérifiez l'aperçu avant d'appliquer. Vous voyez à la fois les fiches à créer / mettre à jour et les relations à ajouter / supprimer. Les erreurs (par exemple, une cible ambiguë avec ses chemins candidats) bloquent l'application.
Export¶
Cliquez sur Exporter. Le filtre courant détermine le contenu : avec un filtre mono-type, une seule feuille de cartes ; sans filtre, une feuille par type présent. Dans tous les cas, le classeur inclut Relations et _Meta et peut être réimporté sans perdre les attributs spécifiques au type.
Import de documents¶
Turbo EA peut extraire des fiches depuis des documents non structurés — PDF, Word, texte brut ou RTF — à l'aide de votre fournisseur IA configuré. Utile pour intégrer un paysage depuis un RFP fournisseur, un rapport d'architecture, un export de wiki, ou tout long texte qui mentionne nommément des applications, capacités, processus, objets de données ou composants IT.
Ouvrez ce flux via Importer ▾ → Document (PDF, Word, texte) dans la barre d'outils.
Fonctionnement¶
Déposez le fichier (ou cliquez pour parcourir). Après analyse, le dialogue affiche trois sections :
- Correspondances existantes — Fiches déjà présentes dans votre paysage que le système a reconnues dans le document, chacune avec un pourcentage de confiance. Lorsque plusieurs variantes du même nom renvoient à la même fiche (par exemple « NexaCore », « NexaCore ERP », « plateforme Nexa Core »), elles sont regroupées en une seule ligne — le texte affiché est la variante ayant la confiance la plus élevée.
- Fiches suggérées — Nouvelles fiches mentionnées par le document mais qui n'existent pas encore. Chaque entrée comporte une case à cocher (cochée par défaut), le type déduit par l'IA (Application, BusinessCapability, BusinessProcess, …), un compteur d'occurrences et éventuellement :
- Une étiquette de cycle de vie indiquant la phase et la date détectées (par ex.
actif · 01/06/2023). Si une phase est trouvée mais pas de date, la date d'import (aujourd'hui) est utilisée. - Un aperçu de description — un résumé d'une ou deux phrases de ce que le document dit de l'entité, affiché en italique.
- Une étiquette de cycle de vie indiquant la phase et la date détectées (par ex.
- Relations proposées — Relations que l'IA a identifiées entre les entités découvertes. Chaque ligne indique la direction (
Source — libellé → Cible) avec une case à cocher. Une relation est automatiquement grisée si l'une des fiches concernées est décochée ci-dessus.
Décochez ce que vous ne voulez pas, puis cliquez sur Importer N sélectionné(s). Le dialogue standard Créer une fiche s'ouvre successivement pour chaque suggestion retenue, pré-rempli avec le nom, le type, la description et le cycle de vie proposés par l'IA. Vous pouvez tout ajuster avant d'enregistrer. Annuler une étape passe à la suggestion suivante ; une fois toutes les fiches créées, les relations activées sont créées automatiquement et vous revenez à la grille d'inventaire.
Mode d'analyse¶
Une petite étiquette à côté du nom du fichier indique quel extracteur a été exécuté :
- Analysé par IA — Votre fournisseur LLM configuré a extrait les candidats et les a résolus contre les fiches existantes. Deux appels LLM par import dans le cas courant (un pour l'extraction, un pour la résolution).
- Analysé par motifs — L'extracteur regex intégré a tourné à la place. Déclenché si :
- l'IA est désactivée dans les réglages d'administration, ou
- l'appel IA échoue en cours d'extraction (la réponse retombe gracieusement pour que vous obteniez toujours un résultat), ou
- plus de 2 000 fiches actives existent dans votre paysage (limite douce du résolveur IA ; la correspondance floue
difflibprend le relais pour garder les invites bornées).
Si l'IA est activée mais mal configurée (identifiant de modèle vide ou clé API manquante pour un fournisseur commercial), le dialogue renvoie une erreur rouge calquée sur le comportement de Suggestions de description par IA. Corrigez le modèle ou la clé dans Administration → Paramètres → IA et réessayez.
Documents volumineux¶
Les documents qui nécessitent plusieurs appels LLM (≥ 30 Ko de texte extrait par bloc) déclenchent une étape de confirmation avant tout appel au fournisseur. Le dialogue affiche le nombre de blocs et l'estimation du nombre d'appels ; cliquez sur Continuer pour poursuivre ou sur Annuler pour abandonner sans consommer de jetons.
Formats pris en charge¶
| Format | Extension | Notes |
|---|---|---|
.pdf |
PDF dont le texte est extractible ; les PDF d'images numérisées ne renvoient pas de texte | |
| Word | .docx, .doc |
Les paragraphes du corps sont lus ; les tableaux et en-têtes intégrés peuvent être ignorés |
| Texte brut | .txt |
UTF-8 |
| Rich Text | .rtf |
Décodé en UTF-8 |
Taille maximale du fichier : 10 Mo.
Permissions¶
L'option « Document » apparaît dans le menu Importer pour les utilisateurs disposant de la permission documents.view. L'extraction IA proprement dite utilise la même configuration de fournisseur que les Suggestions de description par IA et est régie par les mêmes réglages d'administration — voir Suggestions de description par IA ci-dessus pour la mise en place du fournisseur et du modèle.